Apache HBase是Hadoop数据库,这是一个分布式,可扩展的大数据存储。如果需要对大数据进行随机,实时的读/写访问时,可以使用HBase,HBase可以在群集上托管非常大的表(数十亿行数百万列)。
特性
- 线性和模块化可扩展性。
- 严格一致的读写。
- 表的自动和可配置分片。
- RegionServer之间的自动故障转移支持。
- 方便的基类,用于通过Apache HBase表备份Hadoop MapReduce作业。
- 易于使用的Java API用于客户端访问。
- 块缓存和布隆过滤器用于实时查询。
- 通过服务器端过滤器查询谓词下推。
- Thrift网关和REST-ful Web服务,支持XML,Protobuf和二进制数据编码选项。
- 可扩展的基于Jruby的(JIRB)Shell。
- 支持通过Hadoop指标子系统将指标导出到文件、Ganglia、JMX。
集群搭建准备工作
准备工作
| node1 | node2 | node3 | node4 | node5 |
| Master | Master | |||
| RegionServer | RegionServer | RegionServer | RegionServer | RegionServer |
时间同步,hadoop用户免密钥,zookeeper集群,hadoop集群,linux设置。这些在配置hadoop集群的时候都已经配置过了,详情可以参考下hadoop-3.3.0 完全分部署安装这篇文章
centos8打开文件和远程文件数量设置
vim /etc/security/limits.conf
#打开文件的数量限制
* soft nofile 204800
* hard nofile 204800
#打开进程数量限制
* soft nproc 204800
* hard nproc 204800下载HBase,创建Hbase目录,赋予权限。
#利用管理员用户创建Hbase存放目录
mkdir /data/hbase
#赋予权限(hadoop用户)
chown -R hadoop.hadoop /data/hbase下载文件解压缩(我用的hadoop用户启动,你们也可以使用root用户启动)
#进入到hbase存放目录
[hadoop@node1 ~]$ cd /data/hbase
#下载文件
[hadoop@node1 hbase]$ wget https://mirror.bit.edu.cn/apache/hbase/2.3.3/hbase-2.3.3-bin.tar.gz
#解压文件
[hadoop@node1 hbase]$ tar -xf hbase-2.3.3-bin.tar.gz
#进入目录
[hadoop@node1 hbase]$ cd hbase-2.3.3HBase集群设置
Hbase启动设置(可选)
vim ~/.bash_profile
export HBASE_HOME=/data/hbase/hbase-2.3.3
export PATH=$HBASE_HOME/bin:$PATH
#加载下配置
source ~/.bash_profile集群环境变量配置 hbase-env.sh
[hadoop@node1 hbase-2.3.3]$ vim conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk-11.0.9
export HADOOP_HOME=/data/hadoop/hadoop-3.3.0
#是否使用自带zk 默认为true,由于hadoop集群已经配置zk集群,所以不使用自带默认集群。
export HBASE_MANAGES_ZK=falseHBase集群信息配置 hbase-site.xml
[hadoop@node1 hbase-2.3.3]$ vim conf/hbase-site.xml
<configuration>
<!--设置HBase存放的HDFS路径-->
<property>
<name>hbase.rootdir</name>
<!--当前目录不需要自己创建,hbase会自己创建,如果存在目录hbase会进行迁移,可能会出现其他的错误。
zsjcluster是HA集群的名称,做hbase HA需要指定hadoop的集群名称而不是节点名称,需要和core-site.xml 和hdfs-site.xml里面的名称对应。-->
<value>hdfs://zsjcluster/hbase</value>
</property>
<!--设置开启完全分布式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--设置zookpper集群地址-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3,node4,node5</value>
</property>
<!--设置zookeeper通信端口,默认2181-->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!--HBase在zookeeper上数据的目录-->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<!--hbase.tmp.dir和hbase.unsafe.stream.capability.enforce的配置已经进行删除-->
</configuration>需要将hadoop集群中的core-site.xml和hdfs-site.xml放到hbase/conf文件中,也可以使用软连接
ln -sf /data/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml conf/core-site.xml
ln -sf /data/hadoop/hadoop-3.3.0/etc/hadoop/hdfs-site.xml conf/hdfs-site.xml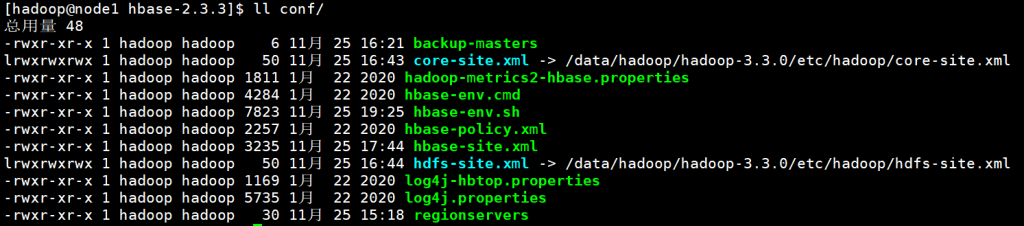
在检查下HA集群的名称是否相同,否则启动会报错误。
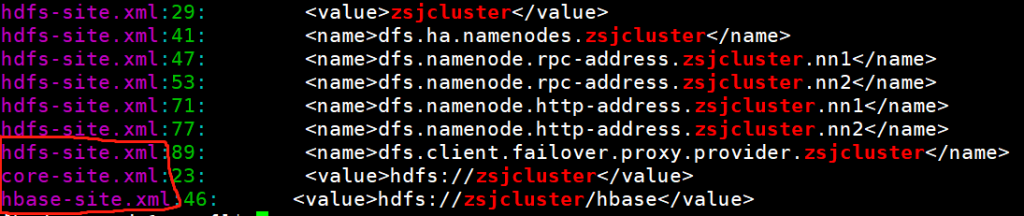
解决日志包冲突问题
[hadoop@node1 hbase-2.3.3]$ rm -f lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar添加备选节点node5(在哪个节点启动哪个节点就是主节点)
[hadoop@node1 hbase-2.3.3]$ vim conf/backup-masters
node5regionServer节点设置
[hadoop@node1 hbase-2.3.3]$ vim conf/regionservers
node1
node2
node3
node4
node5最后同步一下所有的配置文件。可以单独节点重复上述配置也可以使用scp、sync命令
[hadoop@node1 ~]$ cd /data/hbase
#传到node2
[hadoop@node1 ~]$ scp -r hbase-2.3.3 hadoop@node2:`pwd`
#传到node3
[hadoop@node1 ~]$ scp -r hbase-2.3.3 hadoop@node2:`pwd`
#传到node4
[hadoop@node1 ~]$ scp -r hbase-2.3.3 hadoop@node2:`pwd`
#传到node5
[hadoop@node1 ~]$ scp -r hbase-2.3.3 hadoop@node2:`pwd`需要将软连接重新链接下
ln -sf /data/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml conf/core-site.xml
ln -sf /data/hadoop/hadoop-3.3.0/etc/hadoop/hdfs-site.xml conf/hdfs-site.xmlHBase启动
node1节点启动
#需要配置环境变量~/.bash_profile
[hadoop@node1 ~]$ start-hbase.sh
#若没有配置
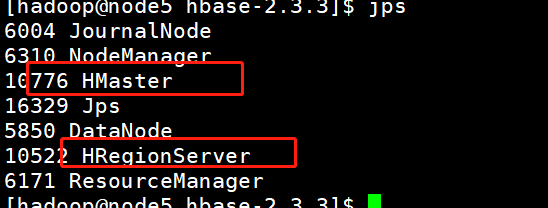
[hadoop@node1 ~]$ /data/hbase/hbase-2.3.3/bin/start-hbase.sh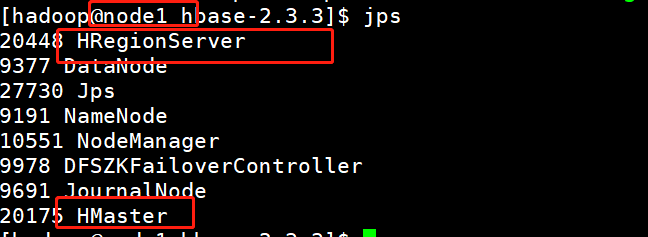
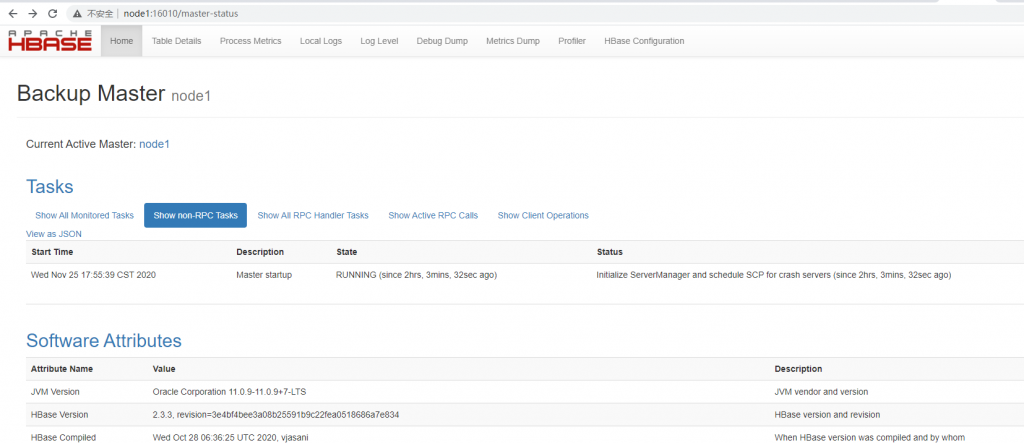
node1、node5节点中的master节点已经启动完成,可以去UI界面看一下:node1:16010/master-status