一、服务器信息
集群是由3台服务器组成,具体信息如下:
| 服务器名称 | 服务器IP | |
| node1 | 172.26.170.101 | |
| node2 | 172.26.170.102 | |
| node3 | 172.16.170.103 |
二、Elasticsearch集群配置
安装包下载
mkdir -p /data/elasticsearch #创建存档es的目录 cd /data/elasticsearch wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz #下载elasticsearch安装包
解压文件
tar -xf elasticsearch-7.9.2-linux-x86_64.tar.gz #解压文件 cd elasticsearch-7.9.2 #进去目录 mkdir data #创建数据存放目录 mkdir logs #创建日志存放目录
添加elasticsearch用户和用户组
groupadd es #添加用户组 useradd -g es es #添加用户并将用户分配到用户组中 chown -R es.es ./* #赋予所有文件es用户和es用户组的权限
修改elasticsearch配置(conf/elasticsearch.yml)
node.name、neiwork.host参数需要写当前节点的信息
vim conf/elasticsearch.yml #将下述配置添加到elasticsearch.yml文件中 #集群名称(各个节点需要统一) cluster.name: dig #节点的名称,各个节点不能重复。 node.name: node-1 #存的是当前目录,也可以不写默认就是当前目录data目录下 path.data: /data/elasticsearch/elasticsearch-7.9.2/data #存到是当前目录,也可以不写默认就是当前目录logs目录下 path.logs: /data/elasticsearch/elasticsearch-7.9.2/logs #写localhost只允许本地访问,写主机IP允许其他访问,如果遇到那个虚拟IP的话没有主机IP可以写0.0.0.0 network.host: 172.26.170.101 #Http协议端口 http.port: 9206 #Tcp协议端口,jar包,集群之间通过Tcp协议进行通信 transport.tcp.port: 9306 #集群列表,以及通信端口,默认为9300 discovery.seed_hosts: ["172.26.170.101:9306","172.26.170.102:9306","172.26.170.103:9306"] #集群节点的名称 cluster.initial_master_nodes: ["node-1","node-2","node-3"]
elasticsearch运行内存修改
vim config/jvm.options
#修改以下内容
#运行内存不要超过32G详情可以看elasticsearch官网。
#https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html
-Xms16g
-Xmx16g防火墙添加开放端口
#开启Http协议端口 firewall-cmd --zone=public --add-port=9206/tcp --permanent #开启Tcp协议端口 firewall-cmd --zone=public --add-port=9306/tcp --permanent #重启防火墙 firewall-cmd --reload
elasticsearch启动测试
#进行测试下看看启动是否有问题 #进去es用户(在2.0版本以后es禁止使用root用户启动) su es #前台启动es bin/elasticsearch
报错:[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]解决
vim /etc/security/limits.conf #修改以下内容 * soft nofile 65535 * hard nofile 65535 * soft nofile 65535 * hard nofile 65535 vim /etc/sysctl.conf #添加下述内容 vm.max_map_count=655360 #重新加载下配置 sysctl -p
在进行测试bin/elasticsearch 已经正常运行没有问题了。
elasticsearch启动
将es添加成服务,直接进行启动,详情可以参考上一篇博客。https://www.zsjweblog.com/2020/10/16/centos8%e5%b0%86elasticsearch%e5%81%9a%e6%88%90systemctl%e6%9c%8d%e5%8a%a1/
#设置为开机自启动 systemctl enable elasticsearch.service #启动 systemctl start elasticsearch.service #关闭 systemctl stop elasticsearch.service #重启 systemctl restart elasticsearch.service
三、elasticsearch集群访问
一般使用kibana或者head访问,kibana会在x-path插件后面讲述。敬请期待
google浏览器中有elasticsearch-head插件,所以现在也没有必要安装head插件了。
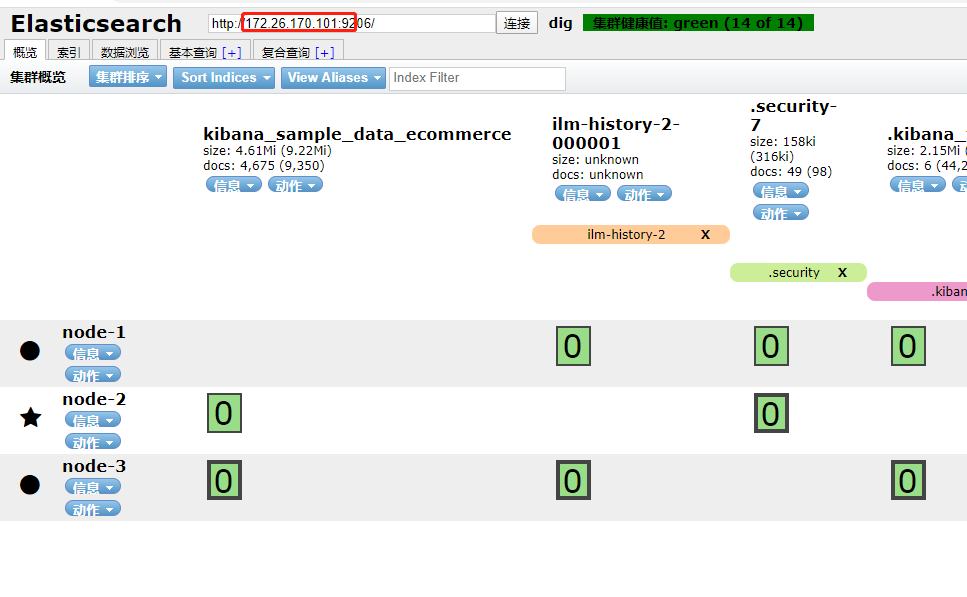
打开head插件直接输入IP地址进行访问
四、IK分词器安装
(1)默认分词器
Elasticsearch默认分词器有以下几种形式:
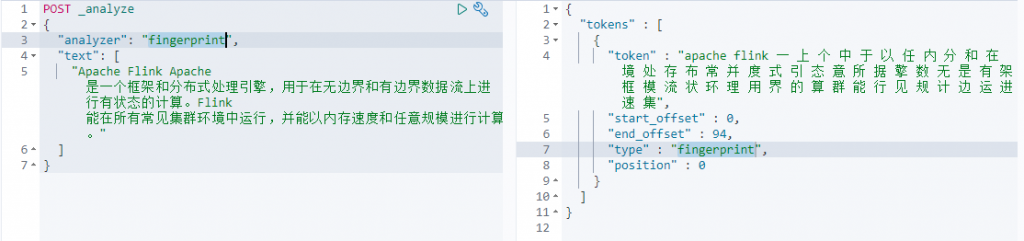
- fingerprint——去除大小写,将汉字单个分开、单词分开并去重。
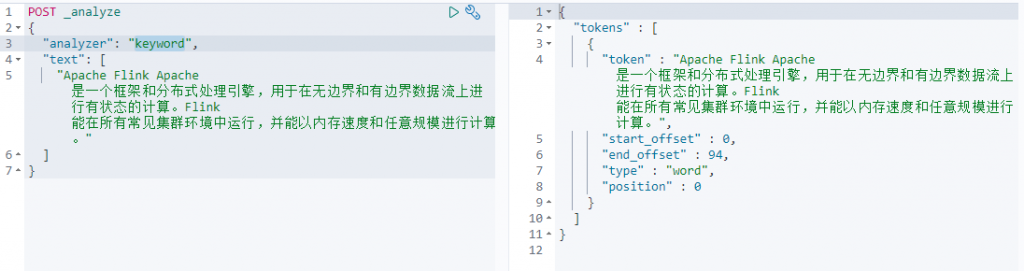
- keyword——不进行分词任何操作,直接原文返回。
- pattern——正则匹配,默认为\W+,也可以根据参数自己定义正则表达式。
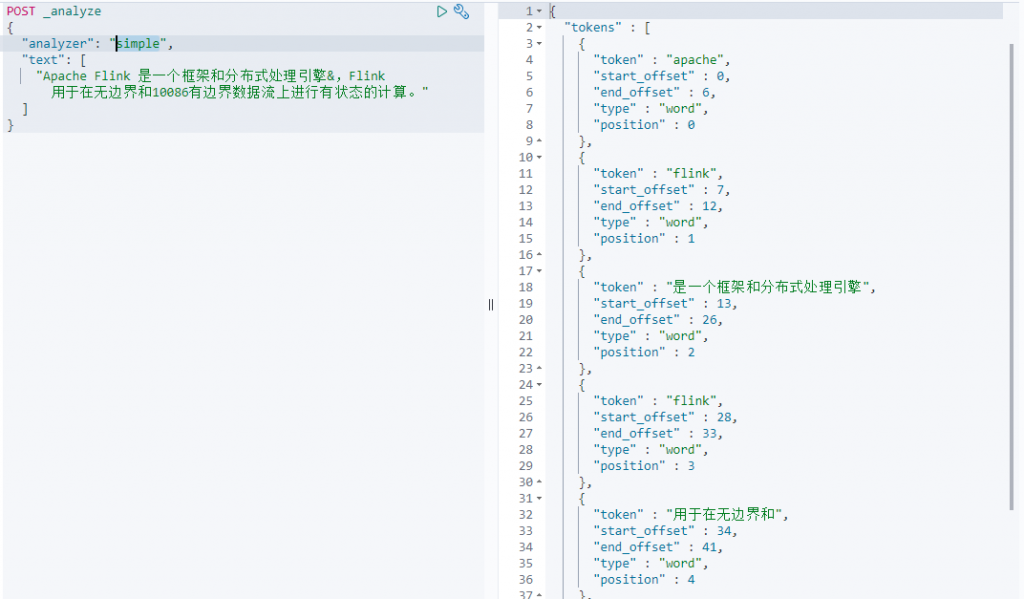
- simple——针对任何非字母进行切割,去除大小写、去除空格、数字,非字符汉字的字符。
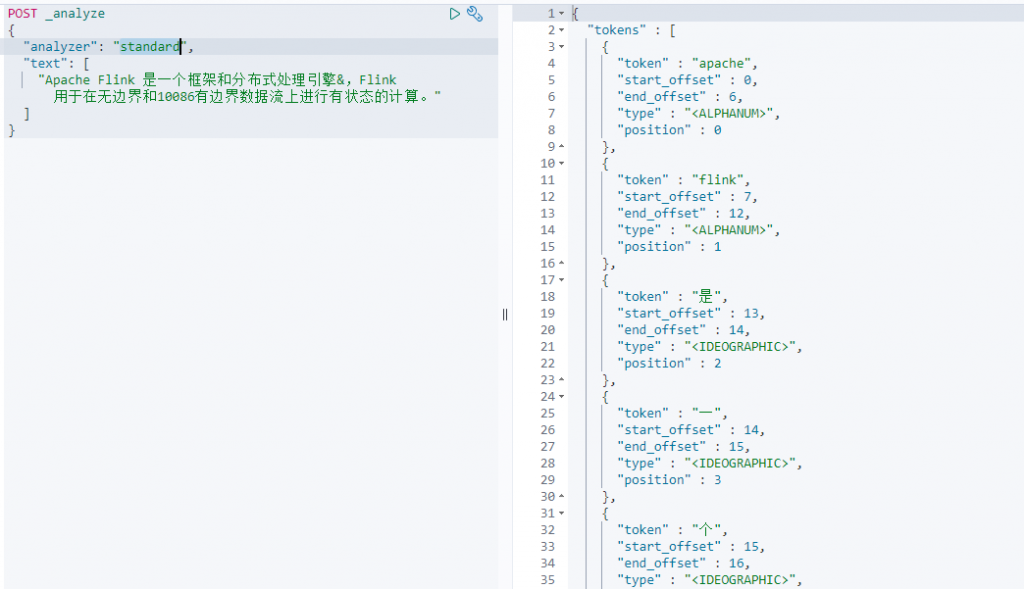
- standard——默认分词器,如果没有指定,则默认为standard分词器。按照单字切分、单词切分、去除大小写。
- stop——停用词过滤(the is a)、去除大小写、数字、特殊字符、以数字特殊字符进行切割。
- whitespace——以空格字符进行切割。
fingerprint(去除大小写、汉字单字切割、单词切割、去重)
keyword(不进行任何操作原样返回)
pattern(需要定义正则表达式默认为\W+)
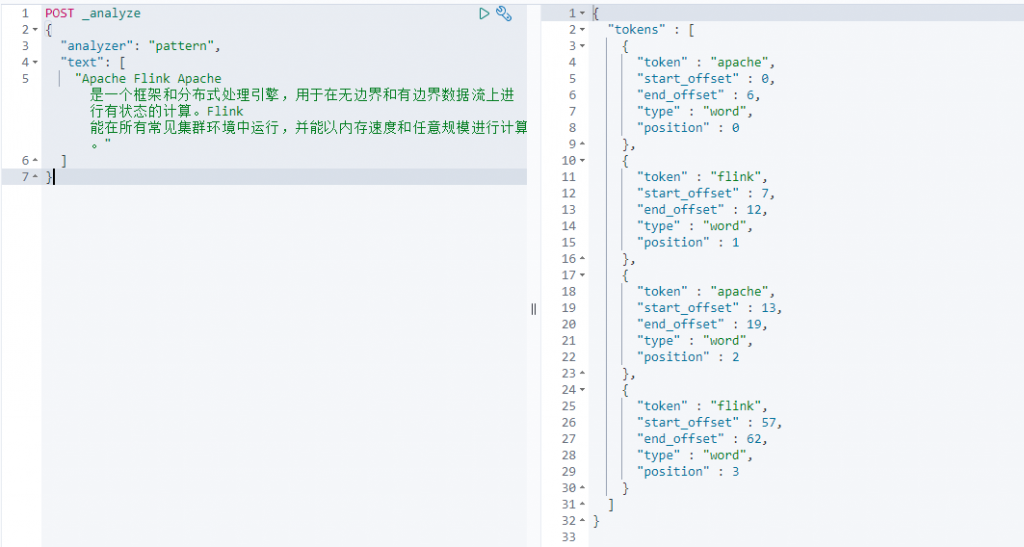
如何自定义正则表达式,先定义一个正则表达式,然后在analzer中配置就可以了
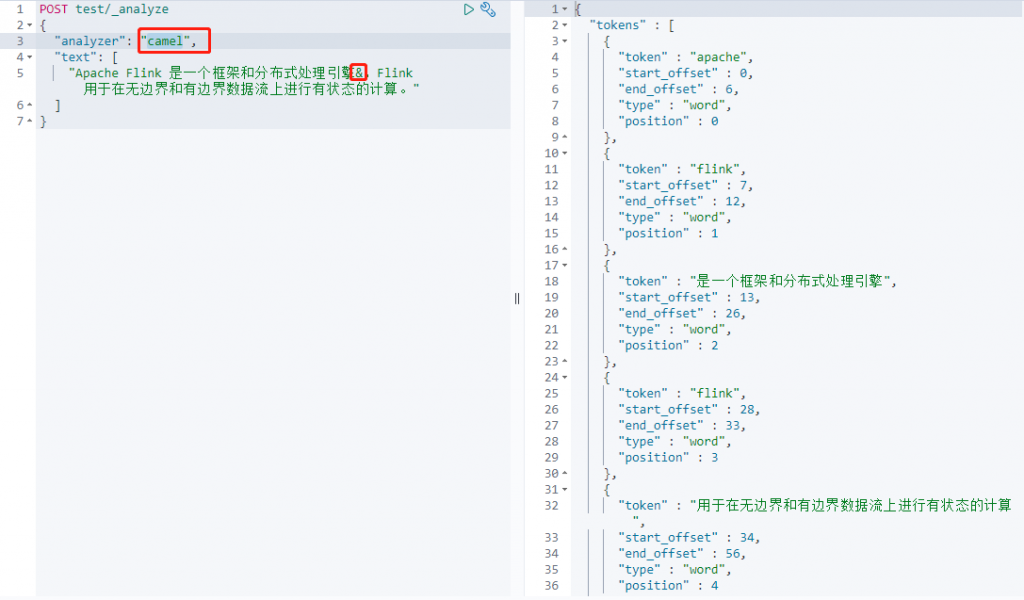
#定义一个名字为camel的正则分词器
PUT test
{
"settings": {
"analysis": {
"analyzer": {
"camel": {
"type": "pattern",
"pattern": "([^\\p{L}\\d]+)" #过滤一些特殊字符
}
}
}
}
}
使用上面定义的名称为camel的正则分词器(可以发现分词以后的结果没有特殊字符了)
simple(根据非单词字符进行切割,去除汉字、字母以外的字符)
standard(默认分词器、按照单字切分、单词切分、去除大小写)
stop(去除停用词——the a is … 、去除大小写、去除数字、特殊字符、以数字特殊字符进行切割)
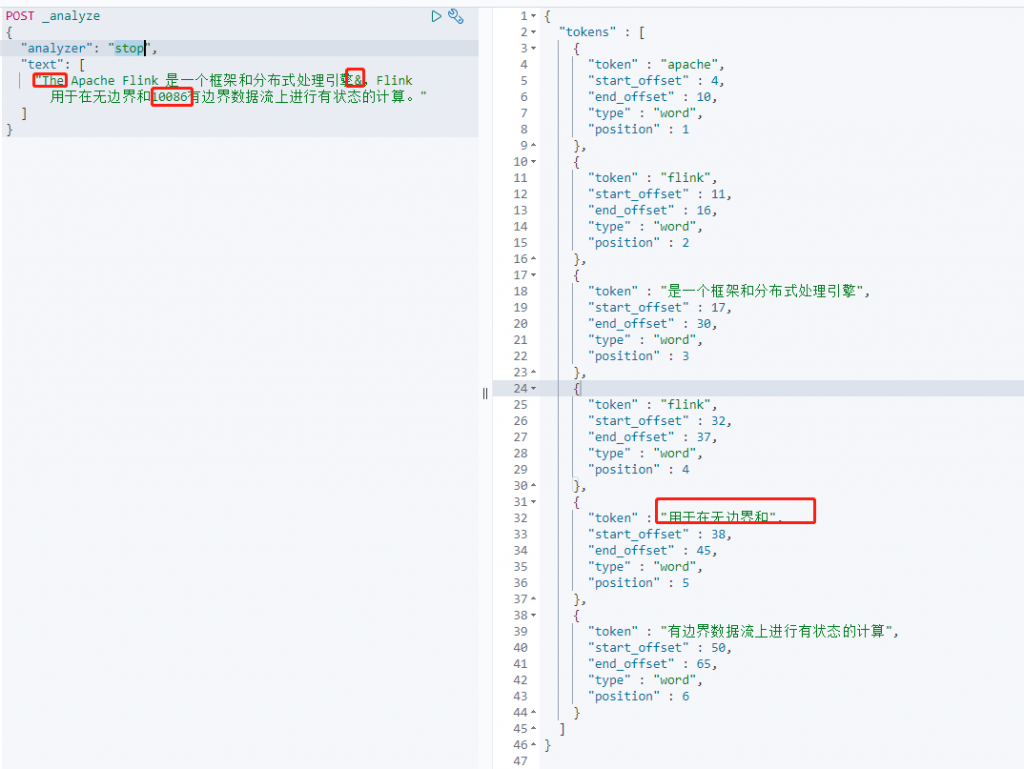
whitespace(以空格字符进行切割)
(2)IK分词器
从默认分词器的例子可以看对中文分词不太友好,无法将中文分词准确。可能分为单个字符,或者是不进行分词,这样大大影响搜索的结果,所以需要安装对中文分词比较友好的IK分词器。
IK分词器安装
#关闭elasticsearch,在elasticsearch各个节点中重复下列操作
#下面的ik版本和安装的es版本要完全一致,否则安装会出现一些错误。
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.2/elasticsearch-analysis-ik-7.9.2.zip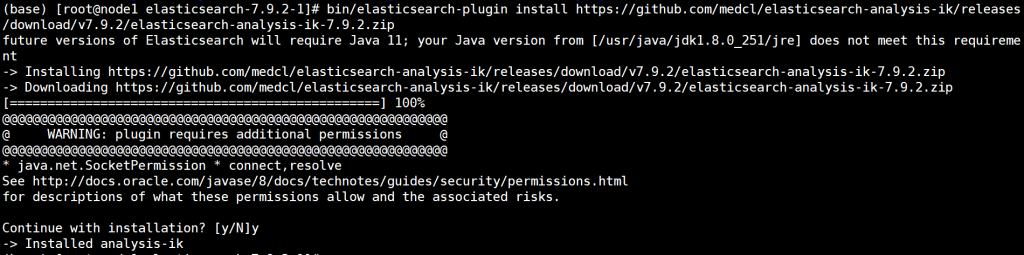
如果你用root用户进行安装的,记得重新给plugins(IK分词器安装目录)文件赋予下es的权限,否则启动会出现问题。

#我当前是在elasticsearch目录中
chown -R es.es ./* 
安装IK完成后启动elasticsearch集群。
#集群中各个节点都执行
systemctl start elasticsearch.sericveIK分词器的分词方式
- ik_smart——最粗粒度切分(切分出尽可能少的词)。
- ik_max_word——最细粒度切分(切分出尽可能多的词)。
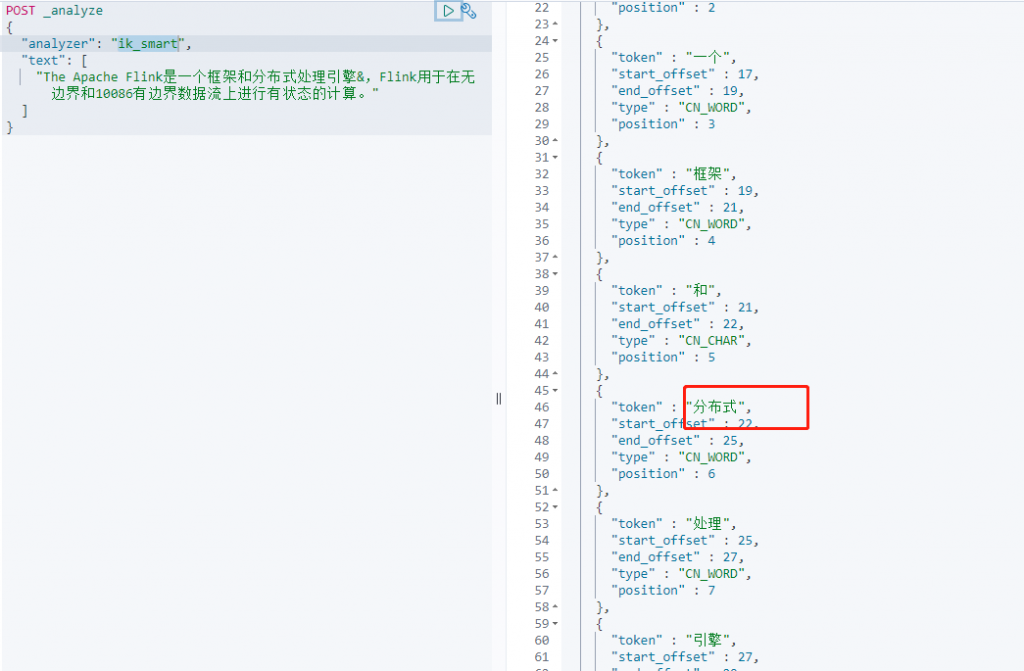
ik_smart(最粗粒度切分)
POST _analyze
{
"analyzer": "ik_smart",
"text": [
"The Apache Flink是一个框架和分布式处理引擎&,Flink用于在无边界和10086有边界数据流上进行有状态的计算。"
]
}
ik_max_word(最细粒度切分)
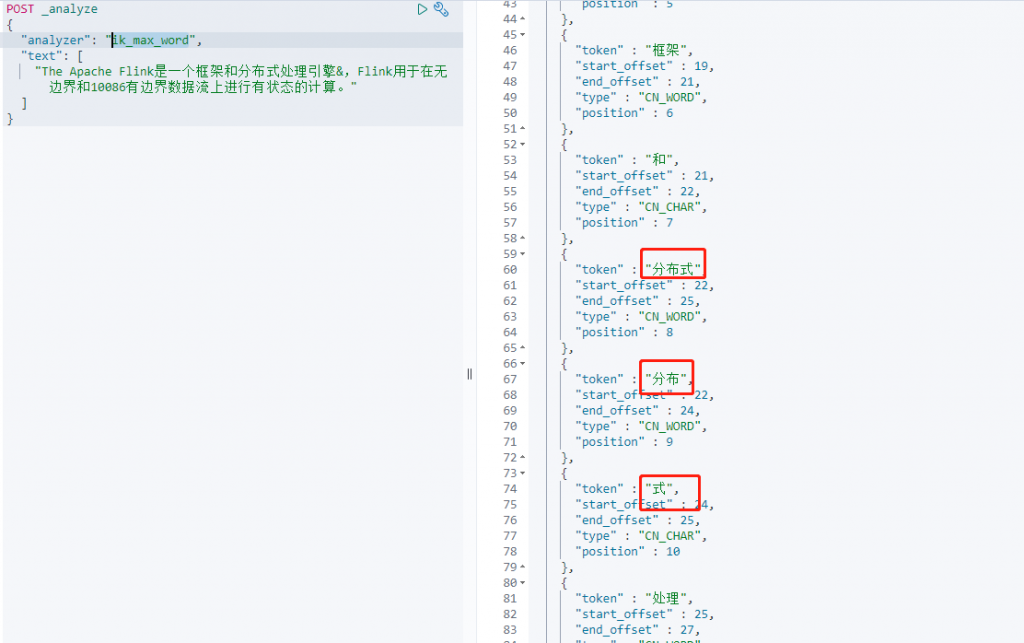
可以看出最粗粒度切分的时候,对切分的词不会再进行切分,而最细粒度切分会对切分以后的词会再次进行切分。
添加扩展词字典和停用词字典(本地词典)
安装IK分词器以后IK分词器的配置文件和分词、停用词字典都在config/analysis-ik/文件夹下。如果需要配置自己的词典或者停用词需要添加自己的停用词文件.dit文件,一行一个词语,使用换行符\n进行换行,并确认扩展词典为UTF8格式。
例:我现在有一个需求希望分词分出《分布式处理》这新得词语,但是上述的分词都没有达到要求,这里我添加一个自己的扩展词文件。
#进入到ik分词器的配置文件中
cd config/analysis-ik/
#添加一个扩展词文件
vim my.dic
分布式处理
#扩展词文件配置到IK分词器中
vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 如果有路径可以写对应路径,多个的话中间用;分割如 my1.dic;my2.dic-->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>重启Elasticsearch集群,配置词典需要在每个节点都配置。重启完成后在测试一下:
POST _analyze
{
"analyzer": "ik_max_word",
"text": [
"The Apache Flink是一个框架和分布式处理引擎&,Flink用于在无边界和10086有边界数据流上进行有状态的计算。"
]
}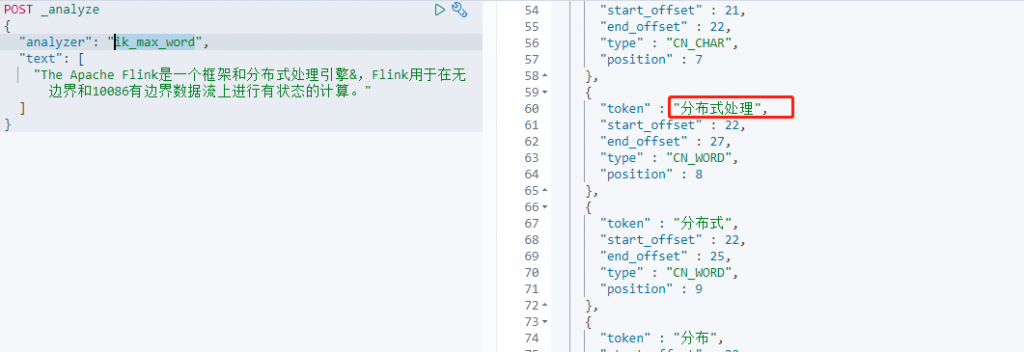
无论是最粗粒度还是最细粒度都多了《分布式处理》这个词语,添加词典完成。
添加扩展词字典和停用词字典(远程词典)
添加远程词典就是你可以动态更新词典,Elasticsearch集群自动去更新词典,不需要在进行重启集群。可以进行动态更新,也不用在每个节点中都存放对应的词典库了。
配置nginx做远程词典(这里创建nginx就不做讲解了)
#添加一个nginx配置文件
vim ik.conf
server {
listen 8092; #端口
server_name 172.26.170.101; #ip
charset utf-8;
location / {
root /usr/share/nginx/html/ik; #词典存放地址
}
}添加一个词典文件
#进入到上述配置的ik远程词典的目录
cd /usr/share/nginx/html/ik
#创建一个目录
mkdir dic
cd dic
#添加一个远程词典
vim my.dic
分布式处理引擎测试词典能否正常访问
#重启ngixn
systemctl restart nginx.service
#测试下是否可以获取到
curl -sL 172.26.170.101:8092/dic/my.dic 
将远程词典添加到elasticsearch集群中(每个节点都需要添加)
#进入到elasticsearch目录
cd /data/elasticsearch
#编辑ik配置文件添加远程词典
vim config/analysis-ik/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典,多个使用;分割 -->
<entry key="remote_ext_dict">172.26.170.101:8092/dic/my.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>各个节点全部添加完成后重启Elasticsearch集群
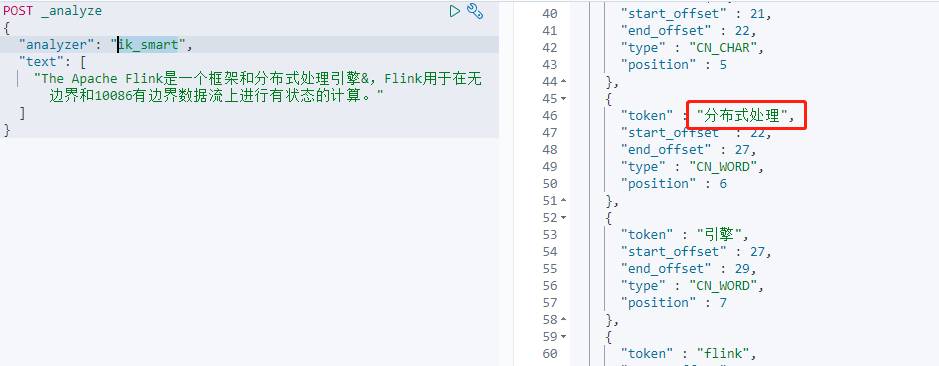
测试分词效果
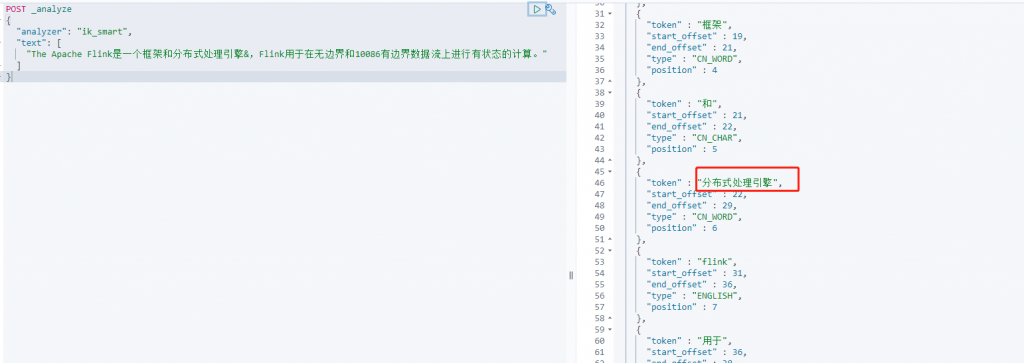
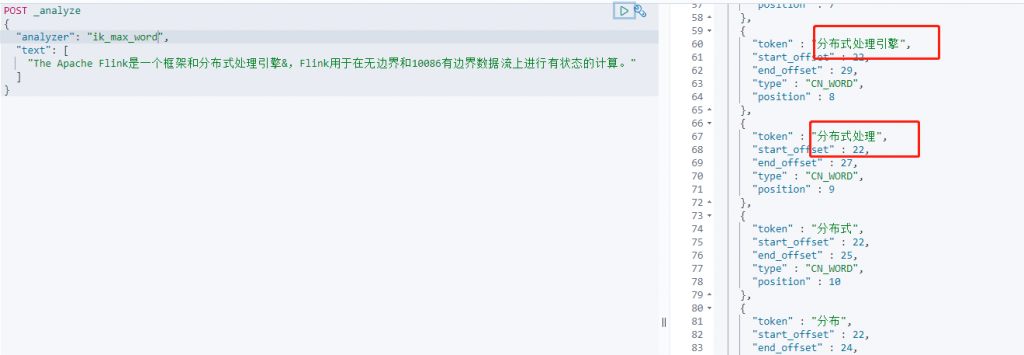
添加新词动态更新
#添加一个新词——有边界数据流
vim /usr/share/nginx/html/ik/dic/my.dic
分布式处理引擎
有边界数据流
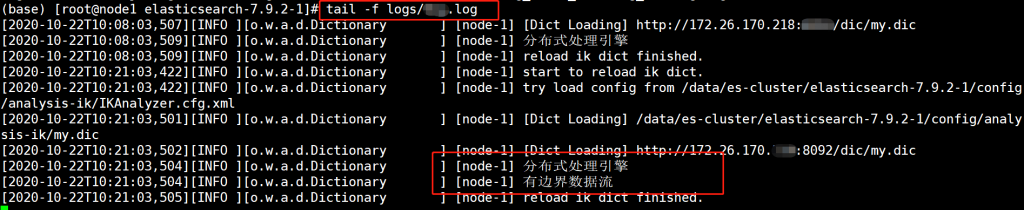
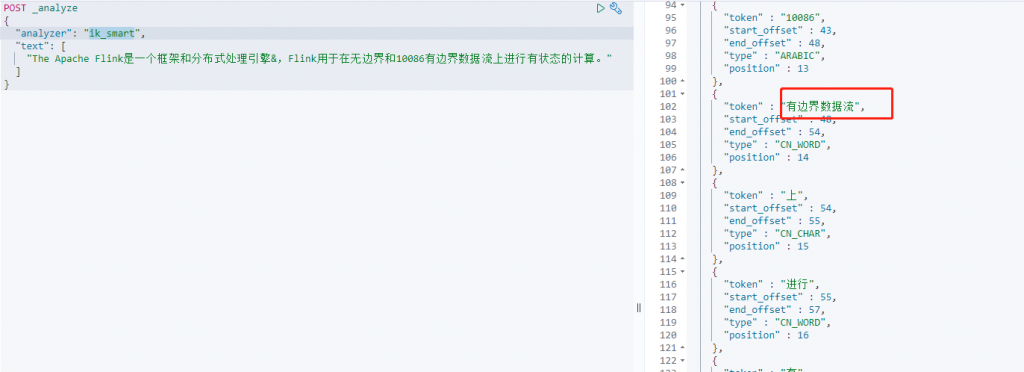
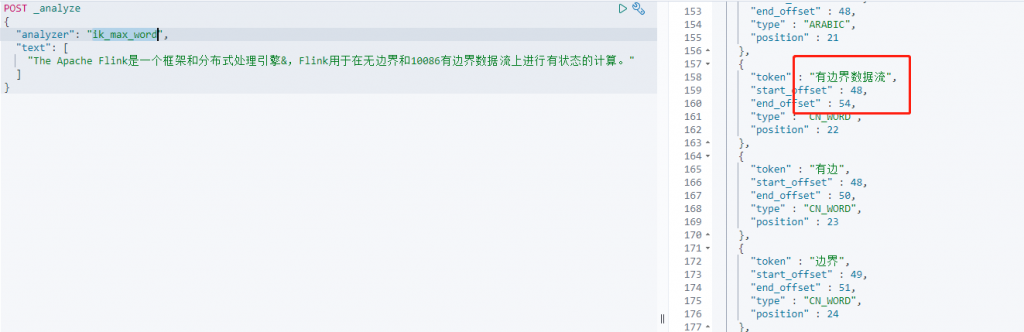
测试出ik_smart和ik_max_word都有新添加的词语,Elasticsearch集群也没有重启,动态添加完成。
更新词典以后,对入库的数据需要进行更新才能对新的词典进行分词
POST index_name/_update_by_query?scroll_size=100